8.4 Stateful/less な変換器
機械学習の研究論文などでは, しばしば問題の単純化のため学習データとテストデータが固定されています. しかし, 実際の我々の業務では常にデータが変動します.
以下のような特徴量の使い方は, 将来も機能するのか注意してください.
- 使えるタイミングが限定されるような特徴量
- ある特定の日付, 時刻に対応する特徴量
- ユーザーIDなど, 値のバリエーションが変わりうるカテゴリカルデータ
これは突き詰めるともっと上流工程でのプロダクトデザインにも絡んでくる話ですが, ここでは機械学習タスクの範囲で説明します.
具体例を挙げましょう. あなたは学習データの変数をいろいろグラフに表したりグループ集計したりして傾向を調べた結果, 今月(例えば8月)の1日のログだけ, 他と大きく違うことが分かりました. そこで当てはまりを良くするため, 「8/1 ダミー」を入れました. しかし, これは来月でも有効でしょうか. 外れ値を吸収し, 過学習を避けるという点では有効ですが, もしかすると周期性のある傾向かもしれません. つまり, 毎月1日はいつもプロモーションがあるので, 定期的にサービス利用が増えているという可能性があります. 見える範囲は限られていることに注意してください(図 8.2).
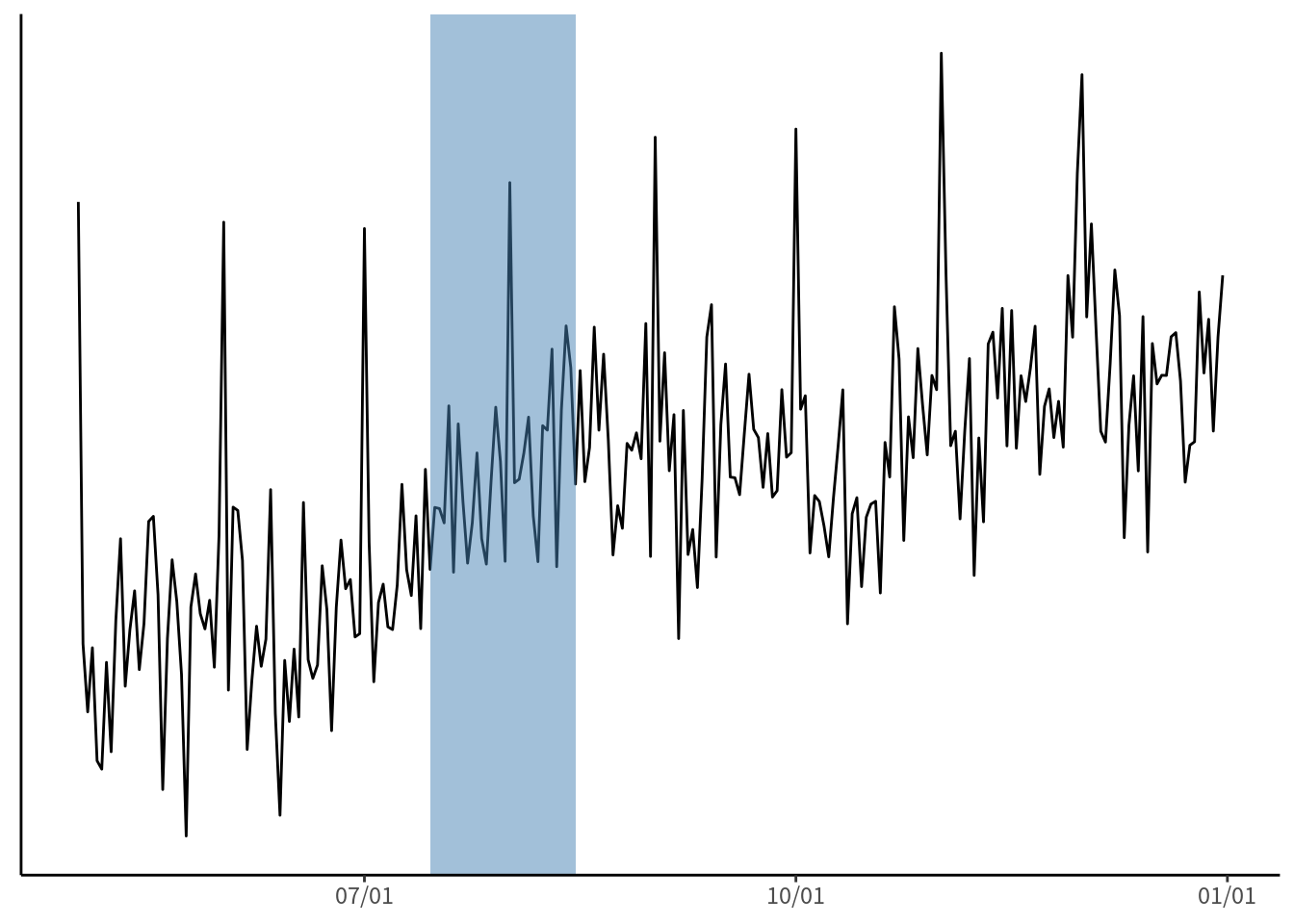
図 8.2: 一時的なイベントか, 周期的なイベントか
2つ目の具体例はこうです. 今, ユーザIDを one-hot encoding, つまりIDごとに1対1のダミー変数で特徴量にすることを考えます. 多くのサービスは常にユーザが新規登録したり, 退会したりするため, 学習データにはないIDが将来のデータで現れます. 例えば pandas.get_dummies() は pandas データフレームの変数をダミー変数に変換してくれますが, 学習データのIDのバリエーション (言い換えるなら要素数 \(\sharp x\)) が変わっていれば, 学習時と次元の異なる特徴量行列を作成してしまいます(表 8.1).
逆に言えば, 訓練データとテストデータを結合した状態で, 両方のユーザIDを変換する処理を挟むことはこの問題を見落としやすく, とても危険です.
一方で, scikit-learn 0.22 以降の OneHotEncoder は (以前私が解説を書いた頃から更新され) 使いやすくなっています. 学習時に存在しなかった値が入力された場合「エラーを返す」「欠損値に置き換える」などから選ぶことができるため, 次元の変動を気にする必要がなくなります. あるいは, 主成分分析やハッシュ変換 (Shi, Petterson, Dror, Langford, Smola, and Vishwanathan 2009; Shi, Petterson, Dror, Langford, Smola, Strehl, et al. 2009; Weinberger et al. 2009) などで次元を固定するという選択肢もありますが, この方法が常に有効とは限りません (詳細は13.4節を参照してください). このように, カテゴリカルデータを特徴量として扱う時は特に注意が必要です.
|
|