2.2 機械学習のワークフロー
機械学習モデルを作るという作業をエンジニアリングとして見た場合, 何度も間違え, やり直すことが前提であるというのが最大の特徴です. 試行錯誤のワークフローを過去多くの人が異口同音に定義してきました.
例えば古くは Chapman et al. (2000) による CRISP-DM モデル(図 2.1), あるいは最近ならば Wickham and Grolemund (2016) は図 2.2 のようなサイクルを規定しています.
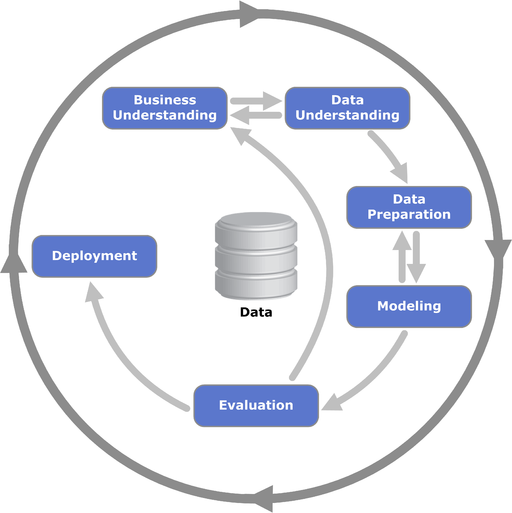
図 2.1: CRISP-DM モデル
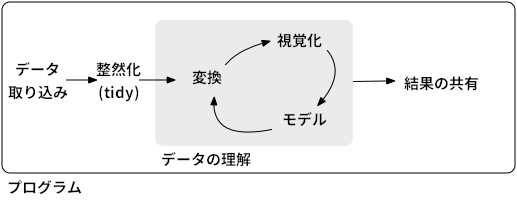
図 2.2: Wickham and Grolemund (2016) によるサイクル図 (拙訳)
それぞれフェーズの数や名称が異なりますが, 共通しているのは, 「十分なパフォーマンスを得るまで試行と評価を何度も繰り返す」という点です.
図 2.2 に今回のインターンのタスクに当てはめるなら, 以下のようになります.
- 「データ取り込み」は TDによるデータ取得に相当する段階 (本稿の 3, 4 章)
- 「整然化」はTDまたは
pandasを使った取得テーブルの整形処理を行う段階. (6 章) - 「データの理解」はや要約統計量やグラフ (7) を見てデータの特徴を掴んだり,
scikit-learnを使って機械学習モデルをいろいろ試し, パフォーマンスを評価する(8, 9 - その結果, 何が悪かったのか, どのモデルやアルゴリズムを使えば改善できるのか, という最も時間のかかる試行錯誤の段階10-13章)
- 「結果の共有」は, 今回のインターンであなたの成果がどう役に立つのかを伝える段階 (14 章)
一回の試行で終わるということはまずありません. またインターンシップは時間が限られているため, 時間配分に気をつけてください.
参考文献一覧
Chapman, Peter, Janet Clinton, Randy Kerber, Tom Khabaza, Thomas Reinartz, C. Russell H. Shearer, and Robert Wirth. 2000. “CRISP-DM 1.0: Step-by-step Data Mining Guide.” In.
Wickham, Hadley, and Garrett Grolemund. 2016. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. 1st ed. Sebastopol, CA: O’Reilly. https://r4ds.had.co.nz/.