7.5 どのようなグラフがあるか
これ以降は以下のプログラムで作成したサンプルデータを使います.
rng = np.random.default_rng(42)
df_sample = pd.DataFrame({
'x': rng.standard_normal(size = 1000)
}).assign(
y=lambda d: rng.lognormal(size=d.shape[0],
mean = d.x, sigma=.1) + rng.normal(size=d.shape[0], scale=2),
z=lambda d: rng.normal(size=d.shape[0], scale=.2) + 0.1 * d.x
).assign(t = lambda d: list(range(d.shape[0])))
7.5.1 箱ひげ図
ある変数の分布の特性を見る方法として, ヒストグラム や 箱ひげ図 があります. 箱ひげ図は、箱 (box) とひげ (whisker, ネコのヒゲのイメージ) によって変数の分布の特徴を視覚化することからその名前がつけられています. 株価の日毎の推移を表すローソク足チャートと似ていますが, 別物です. 箱ひげ図の描き方にはいくらかバリエーションがありますが, ここでは最も古典的な Tukey のものを説明します. 箱部分は、第1四分位点から第3四分位点の範囲を表します. 箱内に第2四分位点 (=中央値) を表記することもあります. ひげ部分は箱の両端からそれぞれ 1.5 IQR の範囲内にある最小値・最大値の点の位置を表します. IQR とは四分位範囲数 (Interquartile Range) のことで、第3四分位点 - 第1四分位点で定義されます. (ヒゲを最小値・最大値とする場合もありますが, ここでは 1.5 IQR の場合を説明します. IQR の場合は両方のヒゲの長さが同じですが, 最大・最小値を用いるとヒゲの長さが異なるのですぐわかります). よく普及している箱ひげ図では, 上下のヒゲからはみ出た点を外れ値と呼びます. 外れ値がある場合, 個別に点で表示することも多いです. よって, 例えば箱やヒゲが長く伸びているものはバラつきが大きいことがわかり, 上側か下側どちらかで外れ値が多いなら分布が歪んでいる, などのことが箱ひげ図からわかります.
これは pandas でも書くことができます.
![]()
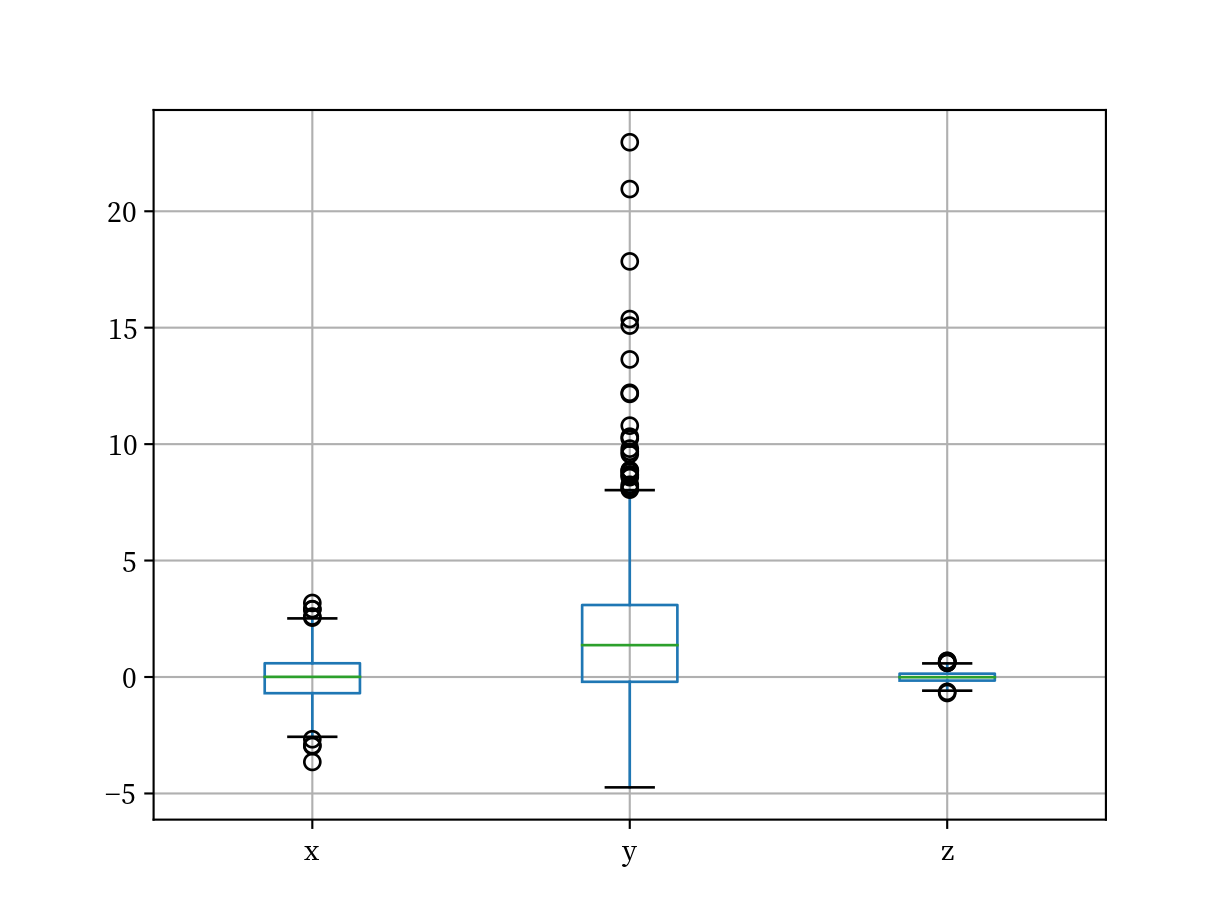
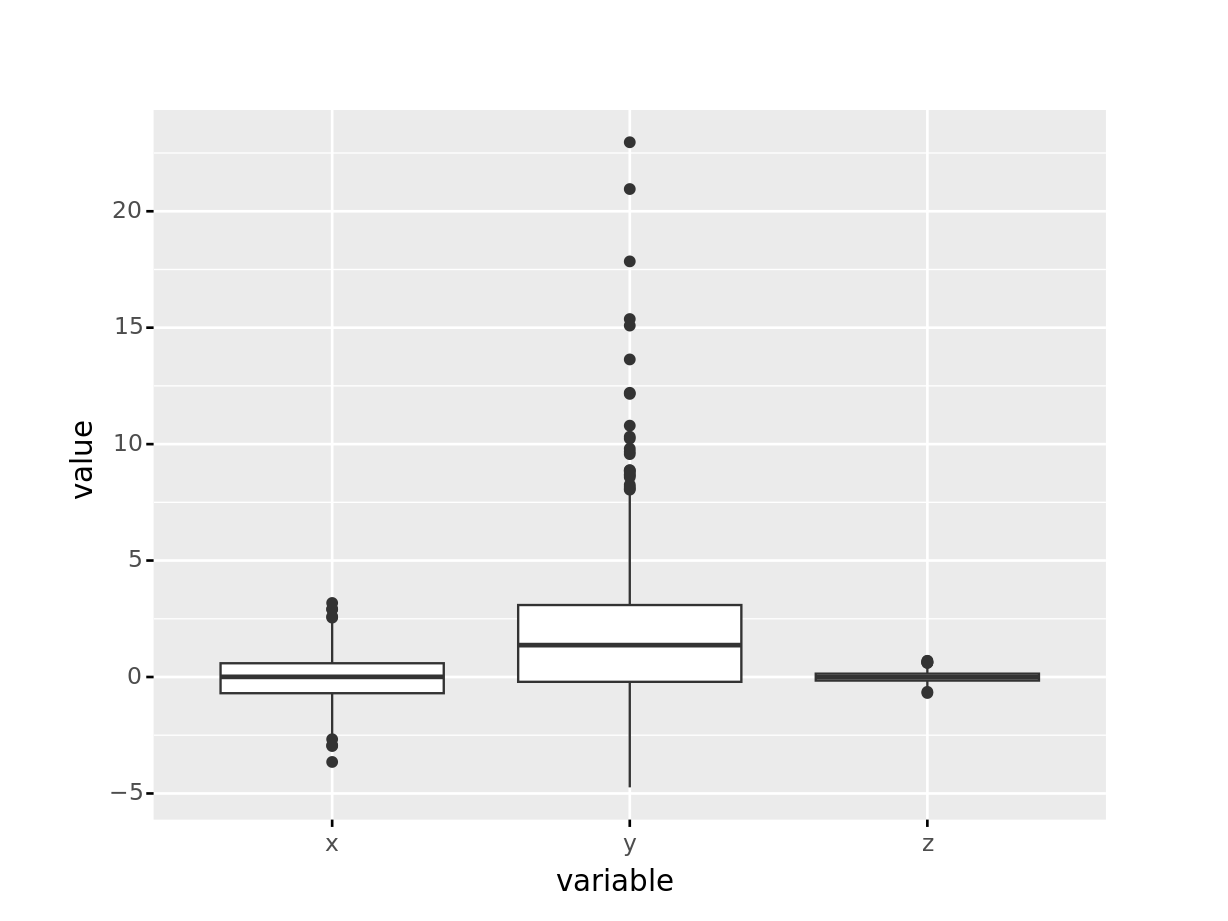
デフォルトで全ての変数の箱ひげ図を掲載するので, 手っ取り早く便利です. さらに plotnine での例を掲載します. 以下のように, x軸はグループ変数, y軸に箱ひげ図に掲載する数値を入れるため, 形式が pandas とは違っています. よって, .melt() でロングにしてから掲載します. これはグループ別に集計した箱ひげ図を掲載したい時に便利になります. 逆に1つの変数だけを表示したい場合, x = '0' などとダミーの定数を与えます. これは plotnine の 箱ひげ図だけに見られる構文で, 他の多くのグラフではグループ化は group= に指定します.

7.5.2 ヒストグラム
ヒストグラム (古い言い方では「柱状図」) は箱ひげ図同様、変数の値の分布を表すものです. ヒストグラムは棒グラフと似ていますが, 別物です. 棒グラフは縦軸横軸で2種類の変数が必要ですが, ヒストグラムは単一の変数の値をいくつかのグループに分けて, 度数を高さで表しています. つまり実際のデータに現れた値をカウントすることで変数の分布そのものを表現しています. このグループをビン (bin) と呼び, 値の幅をビン幅と呼びます. 普通はヒストグラムの各ビン幅は全て同じにします. ビンの設定方法次第でヒストグラムの印象が大きく変わってしまう可能性があることに気をつけてください.
pandas のヒストグラムは, デフォルトで全ての数値変数に対するヒストグラムを作成します.
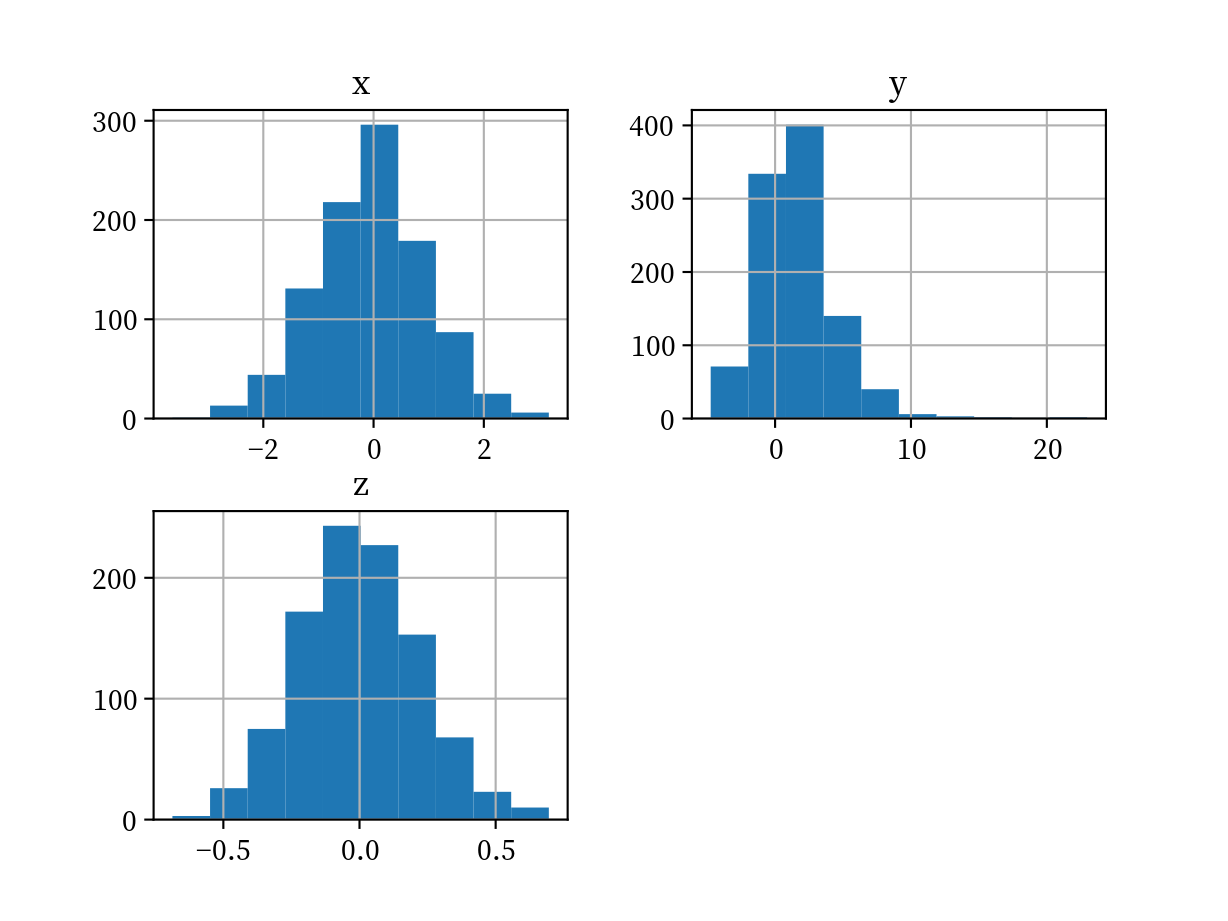
plotnine 1軸に対して1つの変数を対応させるのが原則のため, 1変数ずつのヒストグラムとなります. x のみヒストグラムにする方法を見せます. y='..density..' というのは特殊な参照名で, y軸をカウントではなく相対度数で表現できます.
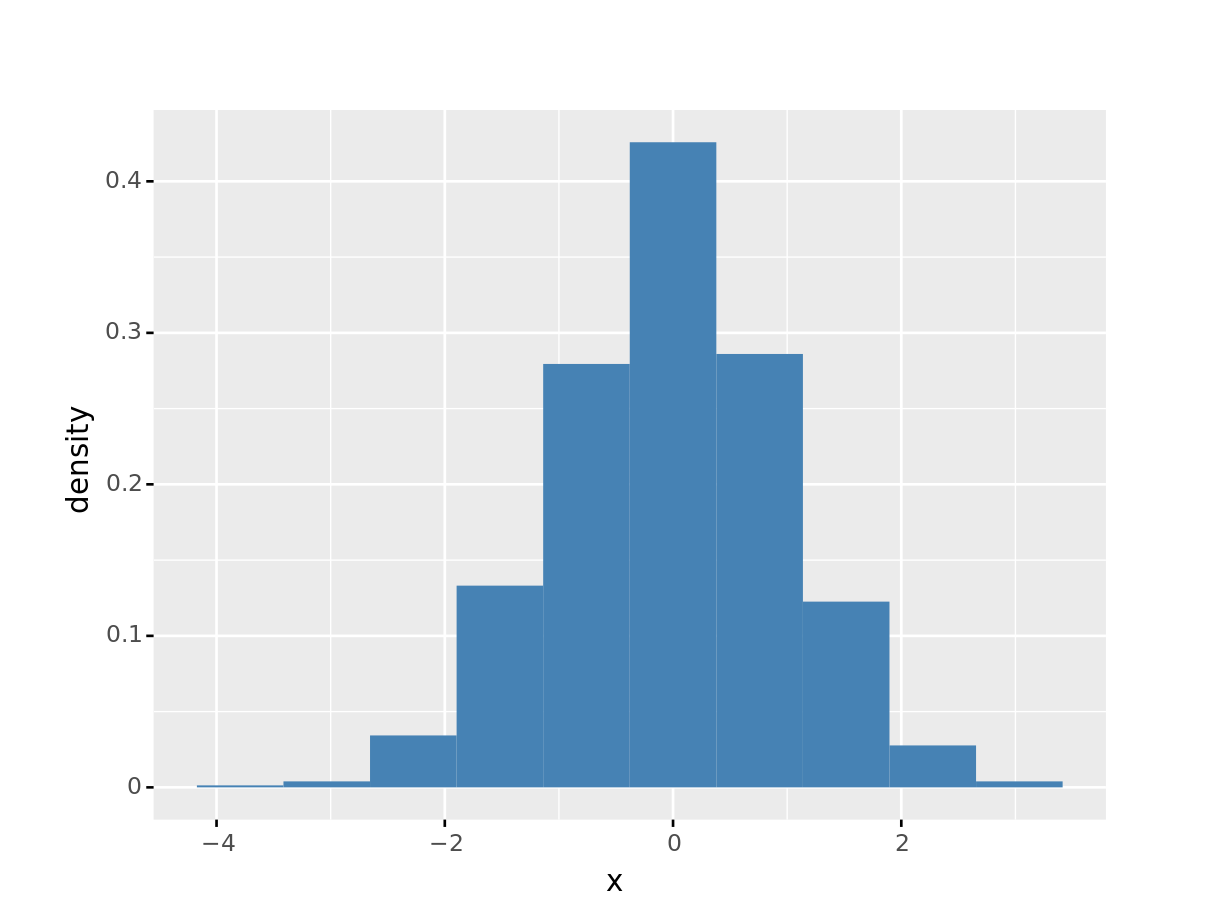
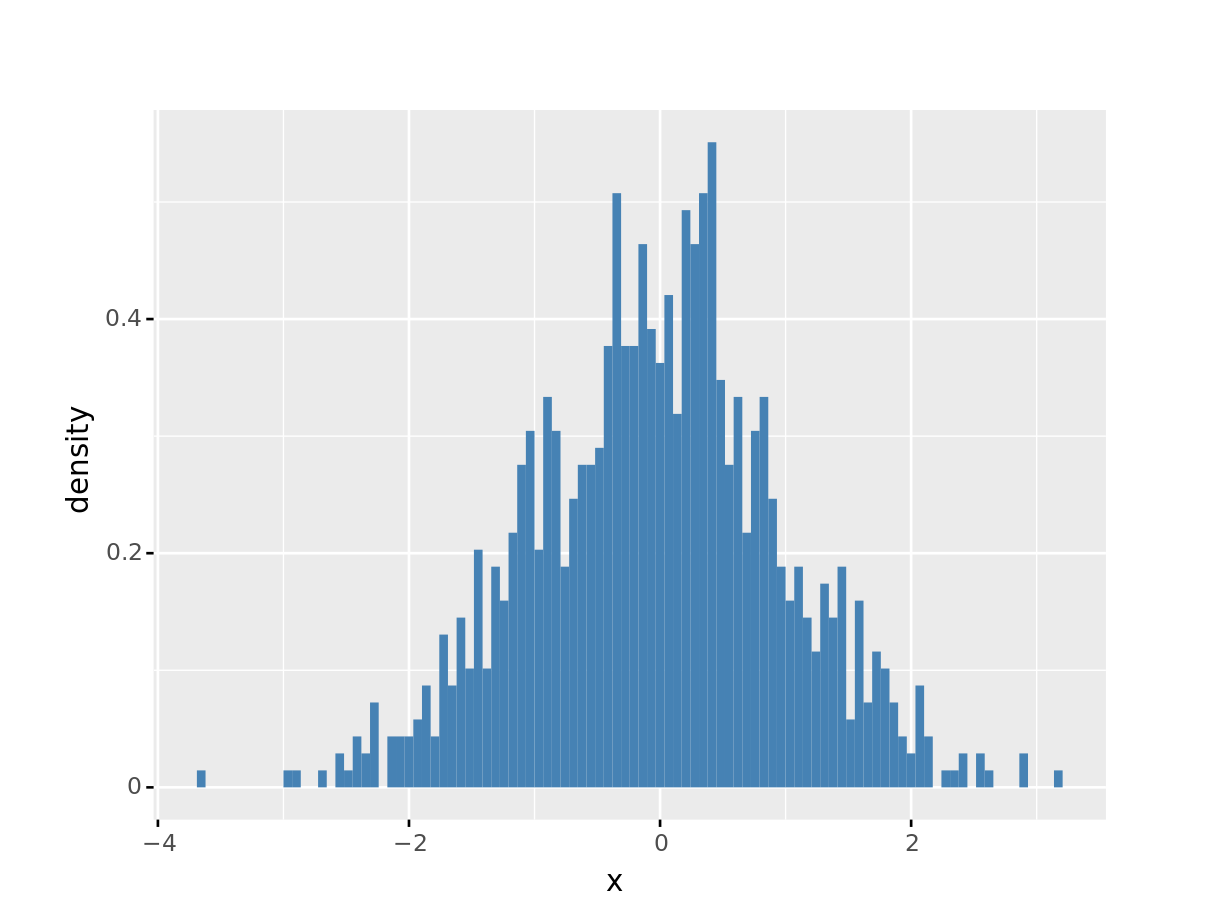
plotnine で複数の変数に対してヒストグラムを作成したい場合は1つ1つ描画するか, データをロング形式に変換してから描画します
ggplot(df_sample[['x', 'y', 'z']].melt(),
aes(x='value', group='variable', y='..density..')
) + geom_histogram(bins=100, fill='steelblue', position='identity'
) + facet_wrap('variable', scales='free')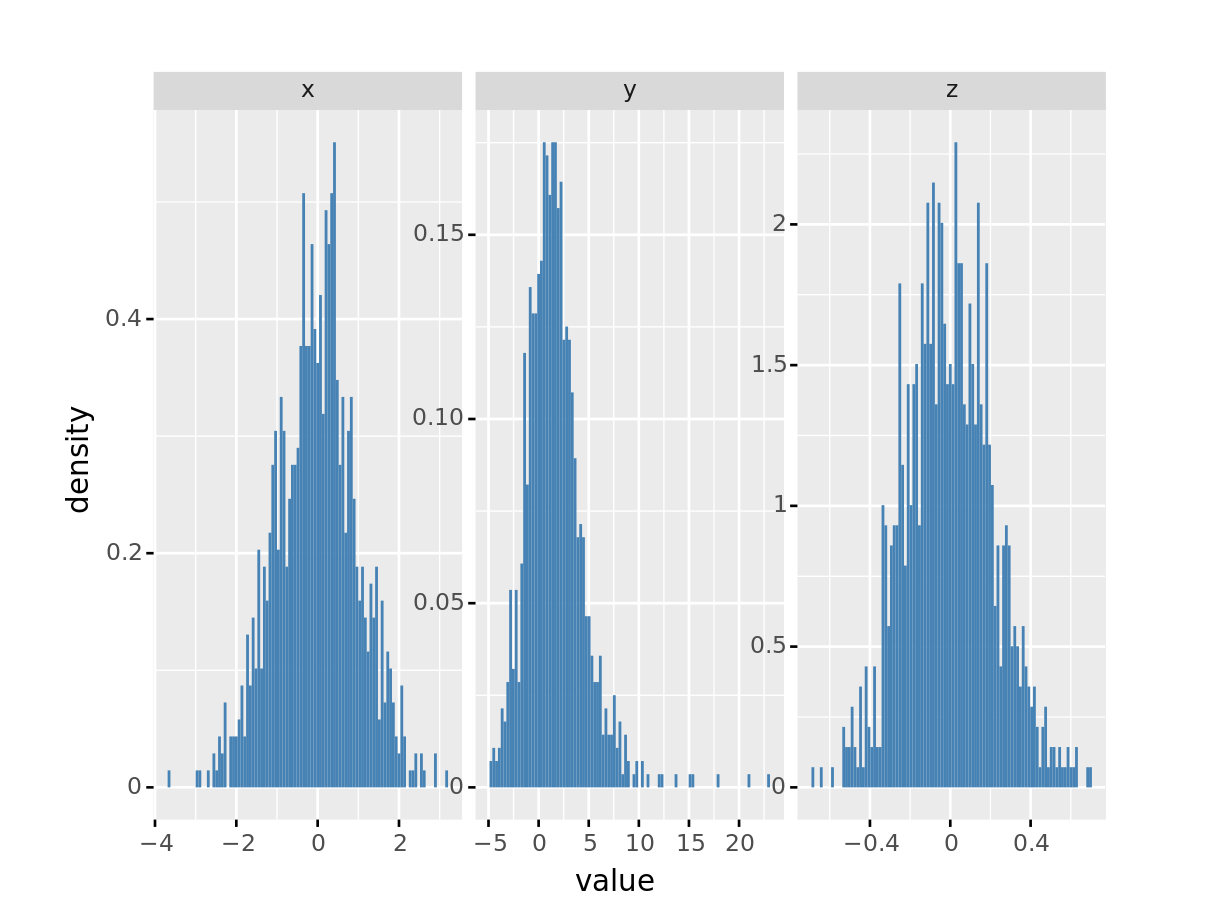
7.5.3 散布図
散布図 (scatter plot) は2つの変数の関係を視覚的に表すために用います. 直交座標上に, 縦軸と横軸の変数の対応する点を描画します。稀に3次元の散布図を用いることもありますが, 基本的に2次元の散布図を使うようにしましょう. あなたのやろうとしていることは多くの場合は2次元で事足ります. 3次元図でないと表現できないことは, 多くの場合不要な情報を落とすことで可能になるからです. 複数の変数の関係を見たい場合は, 相関係数の表のように散布図を並べた散布図行列を使うと良いです. 2変数の関係を表す要約統計量として相関係数がありますが, 相関係数は直線的な関係しか拾えないため, 相関関係を見たい場合は相関係数の計算だけでなく必ず散布図を確認しましょう.
Matejka and Fitzmaurice (2017) は, 要約統計量が全く同じで, かつ散布図が全く異なる面白い例を挙げています(図 7.4). これは著者によるアニメーション21も印象的です.

図 7.4: 要約統計量が全て同じな散布図 (Matejka and Fitzmaurice 2017)
plotnine は geom_point() で散布図を描けます. ここでは z の値で点を色分けすることで, 擬似的に3次元のデータを表現することができます.
散布図行列を見たい場合に限れば, plotnine より pandas のほうが手っ取り早く表示できます.
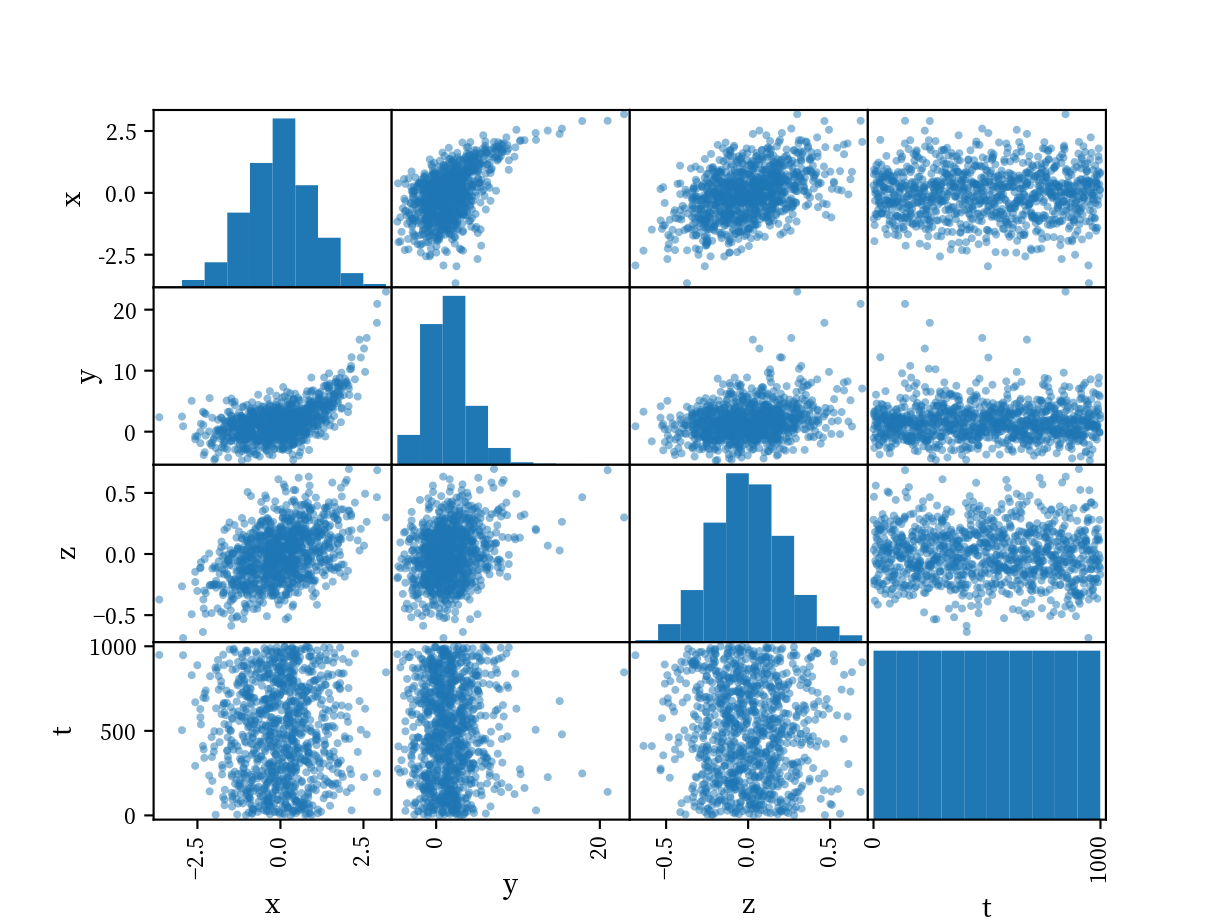
7.5.4 2変数の視覚化
2つ以上の変数を組み合わせたグラフは散布図以外にもいくつもあります. また, 1つの変数をグループごとに分けて集計するということで2軸のグラフを作ることもできます.
散布図以外で非常によく使うのが棒グラフ (bar chart) と折れ線グラフ (line chart) です. これらのグラフはやはり
pandas や plotnine で簡単に描画できます.
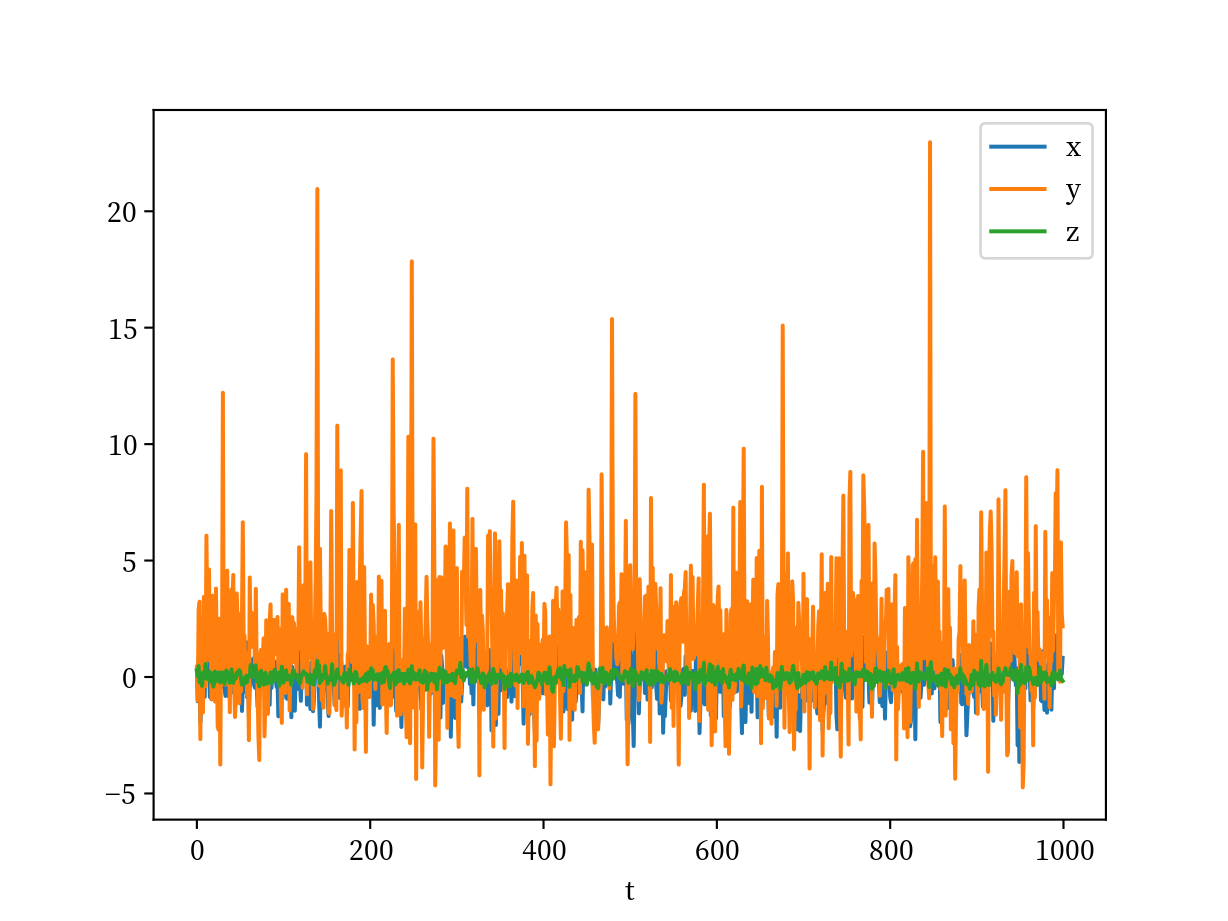
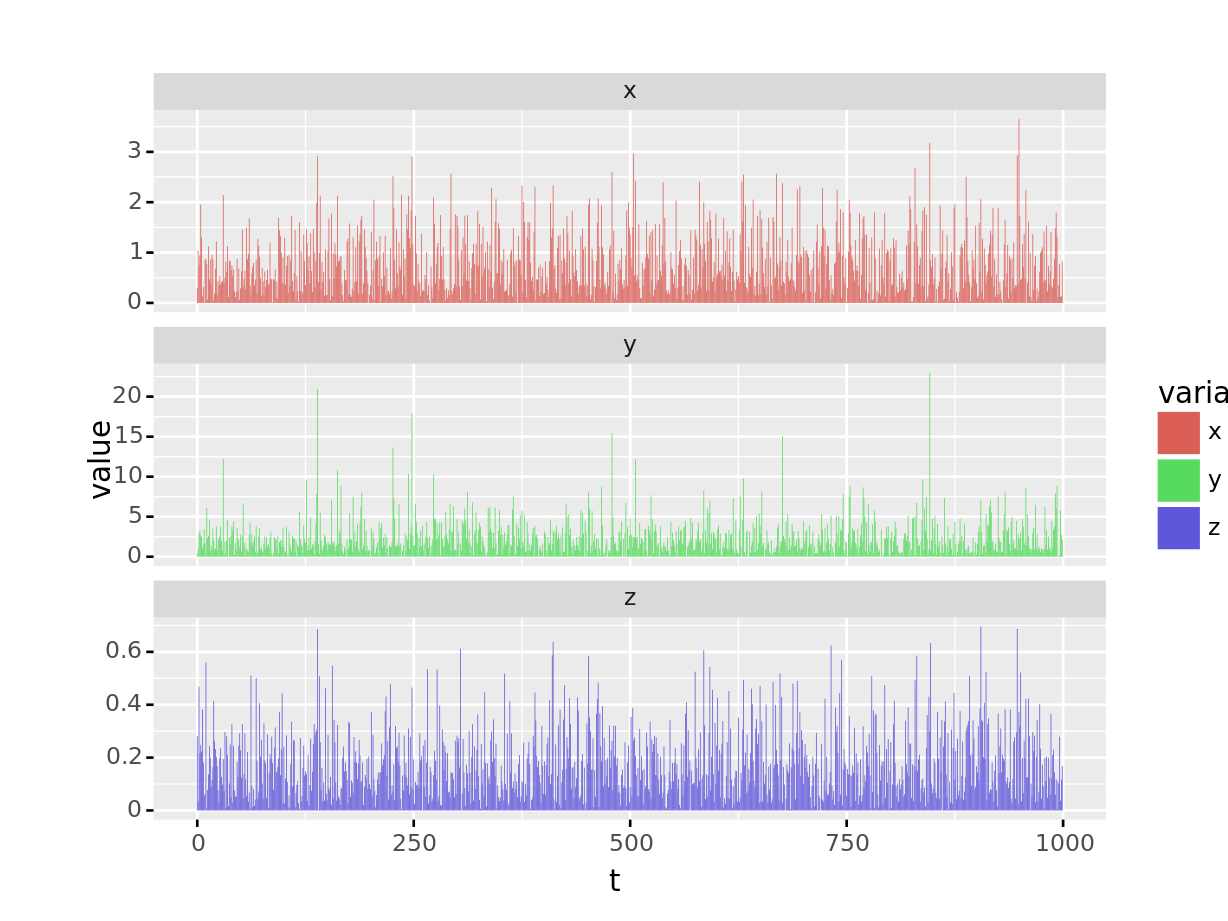
これは少々やっかいです. y のみスケールが他と違うため, 特性を掴みづらいです. matplotlib で書き直すことも可能ですが, より簡単に subplots=True を使います
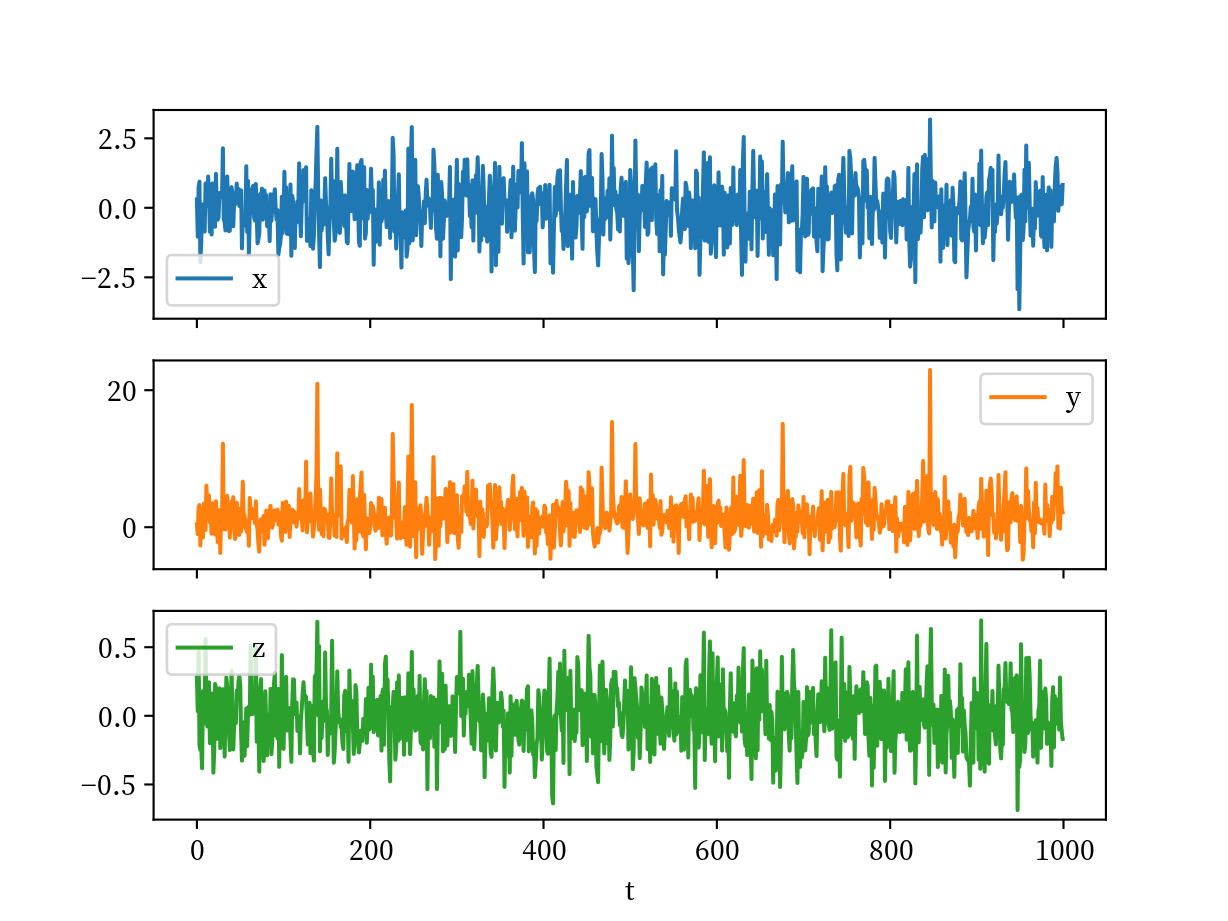
plotnine では facet_wrap() を使い, 別々に表示します. 以下のように, scales='free_y' と指定すれば, それぞれのy軸スケールが可変になります.
ggplot(df_sample.melt(id_vars="t"),
aes(x='t', y='value', group='variable', color='variable')
) + geom_line() + facet_wrap('variable', scales='free_y', ncol=1)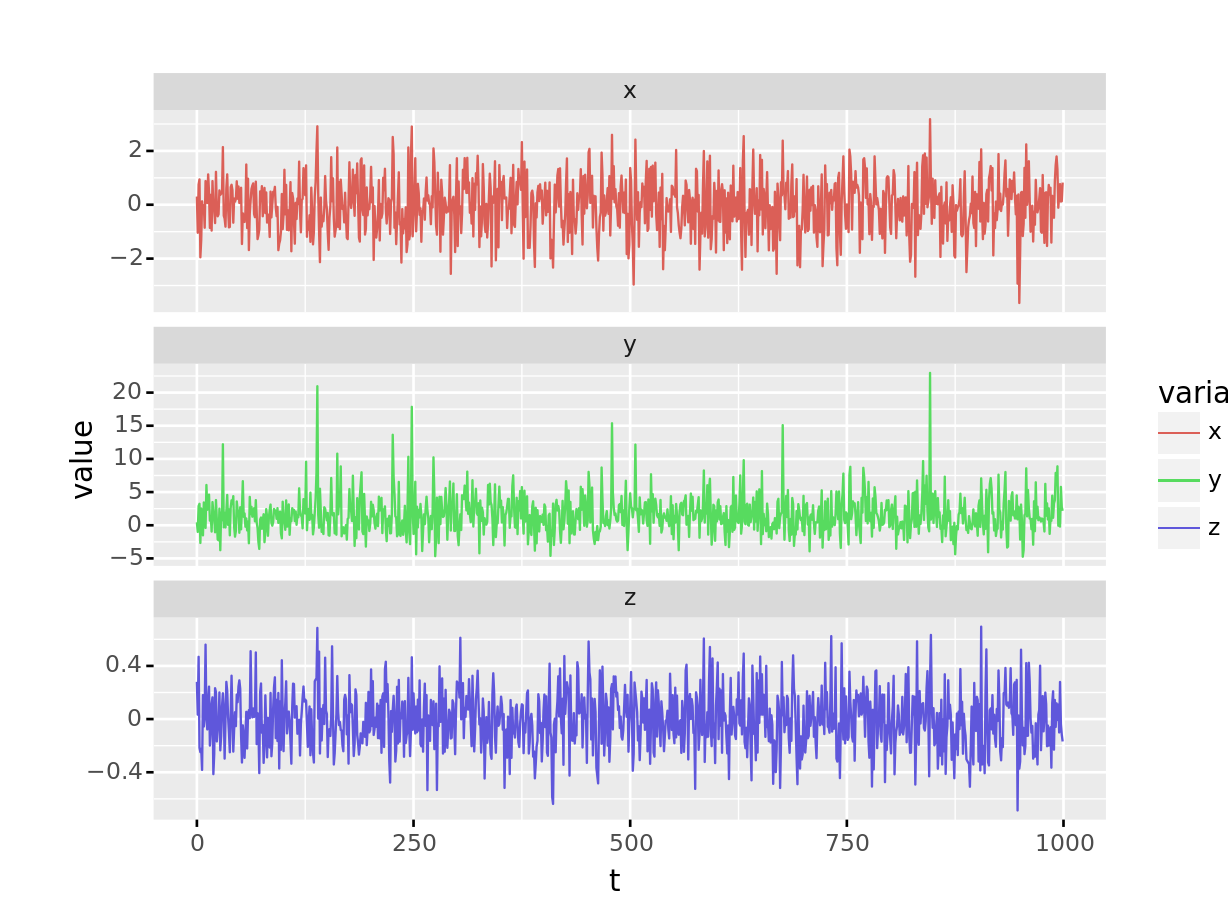
棒グラフも同様に .plot.bar() や geom_bar() で実行できます. 構文はほぼ同じですが, pandas では棒グラフはx軸のラベルが見づらいので注意が必要です. これはもともと棒グラフがx軸に連続的な変数を設定することを想定していないためです. 一方で plotnine も, デフォルトではy軸をヒストグラムのようにカウントした件数にしてしまうため, stat='identity' が必要になります.
ggplot(df_sample.melt(id_vars='t').assign(value=lambda d: d.value.abs()),
aes(x='t', y='value', group='variable', fill='variable')
) + geom_bar(stat='identity') + facet_wrap('variable', scales='free_y', ncol=1)